在强化学习的舞台上,一场智慧与技巧的较量正在悄然上演。通过精心选择行为序列,人工智能将分数推向巅峰。想象一下,我们能够将这种前沿技术应用于训练一款无所不能的游戏AI,它将在Qbert游戏中大显身手。每一步,它都要精确计算操作,操控那个橙色的光标,巧妙地避开紫色的敌人,同时点亮所有的立方体。

面对深度强化学习中的挑战,如雅达利游戏,进化策略(Evolution Strategies)已成为强化学习的有力竞争者。本期论文提出的进化策略不仅旨在训练单一代理,更是在并行训练所有代理,这种高效的方法仿佛大自然的进化过程,通过优胜劣汰,让表现最出色的代理繁衍出新一代。
Open AI的最新研究显示,自然进化策略在深度强化学习的众多手段中,同样能独树一帜。本期论文采用的进化策略证明了,即便是古老的进化策略,也能在最终成绩上交出令人满意的答卷。

令人振奋的是,经过长达5小时的训练,我们发现这款算法不仅能够掌控游戏,还能以极具创意的方式击败Qbert中的机器人玩家。
当它为了诱敌而牺牲自己时,一个小小的故障却带来了惊喜。原本它应该因此丧命,但这个BUG却让它侥幸逃脱。

厉害!AI竟然给自己续上了命。
还有一项令人惊叹的技术,它会在特定位置来回跳跃,然后突然改变路径。它发现并利用了一个前所未有的严重BUG,在完成第一阶段后,它以一种看似随机的模式在周围跳跃。不久后,我们发现游戏并未进入下一阶段,那些方格开始闪烁,人工智能似乎可以随心所欲地获取高分。
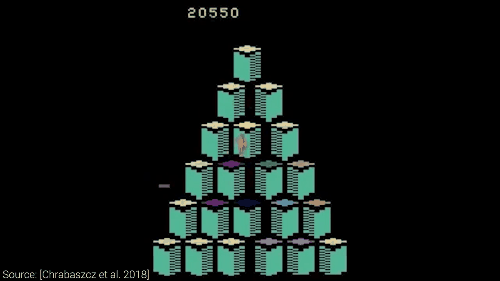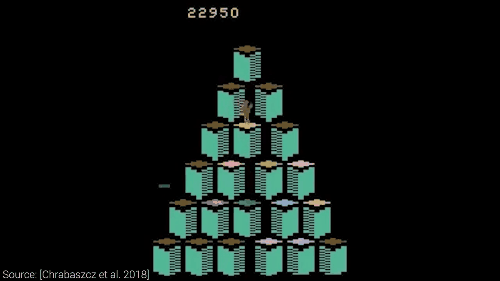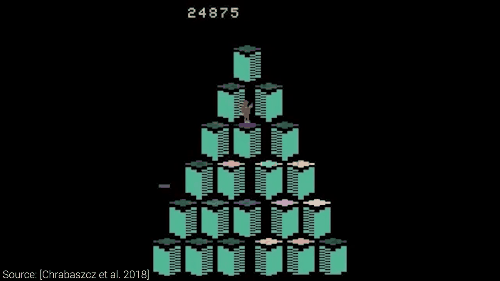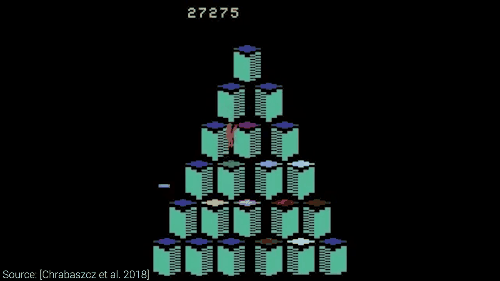
分数蹭蹭往上涨
通过进化策略,AI 可以轻轻松松搞定诸如像雅达利这样的游戏,甚至还能发现 Bug,简直是开了挂一般的存在。
 IGN揭晓TOP100游戏排名,61-40揭晓《守望先锋》上榜
IGN揭晓TOP100游戏排名,61-40揭晓《守望先锋》上榜
 《神秘海域》电影上映悬念重重,上映日期成谜
《神秘海域》电影上映悬念重重,上映日期成谜
 摩尔庄园高效灌溉秘诀全解析
摩尔庄园高效灌溉秘诀全解析
 原神秘境成就解锁秘籍
原神秘境成就解锁秘籍
 博本G神CJ再燃战火,铸就电竞传奇品牌
博本G神CJ再燃战火,铸就电竞传奇品牌
 萌小叽网易CC直播,共赴《炉石传说》广州黄金赛之旅
萌小叽网易CC直播,共赴《炉石传说》广州黄金赛之旅
 CJ盛会史艾田畑端倾情演讲,《FF15》备受期待
CJ盛会史艾田畑端倾情演讲,《FF15》备受期待
 B社预告《辐射4》独享核子饮品,狂欢节畅饮时刻
B社预告《辐射4》独享核子饮品,狂欢节畅饮时刻
 2017年DX12驱动游戏现状,面临挑战?
2017年DX12驱动游戏现状,面临挑战?
 《影之刃3》解锁小厮创建攻略分享
《影之刃3》解锁小厮创建攻略分享
 光遇魔法蛋糕效果时长揭秘
光遇魔法蛋糕效果时长揭秘
 《无尽战区》不限号测试今日开启,CG动画完整版同步揭晓
顽皮狗巨作,《神秘海域4》剧情巨变,主创离职引波澜
《无尽战区》不限号测试今日开启,CG动画完整版同步揭晓
顽皮狗巨作,《神秘海域4》剧情巨变,主创离职引波澜
 微软突解狮头工作室,员工震惊不知情
虎牙户外主播张是非玉雕LOL英雄,陈赫预订互动惊喜
微软突解狮头工作室,员工震惊不知情
虎牙户外主播张是非玉雕LOL英雄,陈赫预订互动惊喜
 《精灵盛典》魔化之地高效刷怪指南,快速通关秘籍揭晓
《精灵盛典》魔化之地高效刷怪指南,快速通关秘籍揭晓